正在更换,请稍后
最新粉丝
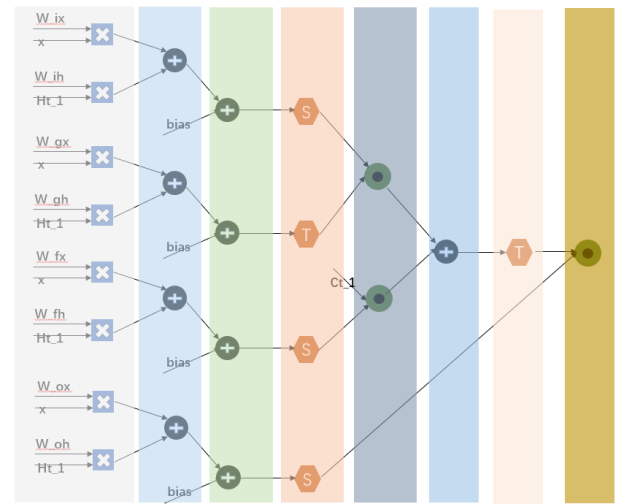
LSTM也是一个多层网络,在实际应用中网络会更复杂一些。
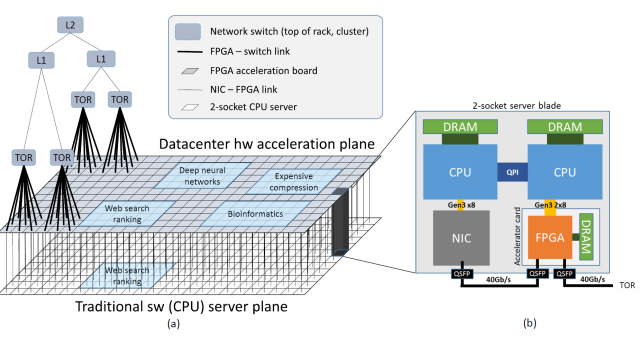
DNN加速器的设计一直在两个方面使力:通用架构和高效性能。
随着5G通信技术的发展,云计算和边缘计算业务也将快速增长。
Lower操作完成从高级算子(relay)到低级算子(TOPI)的转化。
内存分配分为两种情况,一种是can_realloc为真,即可以复用内存,另外一种是不可以复用内存的。
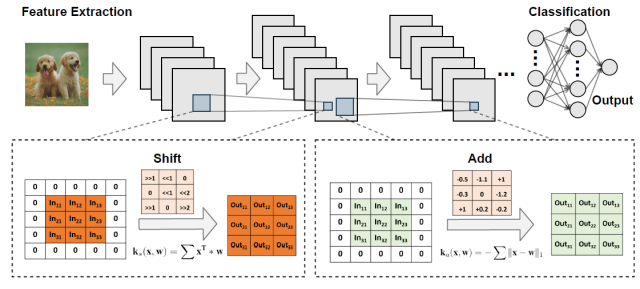
在硬件设计中,乘法计算是很消耗能量和资源的。
Pass是TVM中基于relay IR进行的优化,目的是去除冗余算子,进行硬件友好的算子转换。率。
TOPI是TVM自身的一个算子库,这些算子可以通过te来进行表达,类似于numpy的方式。
TVM前端的输入是protoBuf格式的二进制文件,这个文件描述了由tensorflow构建的神经网络的结构。
Schedule是和硬件体系结构相关的一些列优化。
如果是copy节点,那么不进行lower处理,直接返回CachedFunc封装。
模型的输入是一个后缀为pb的文件,它是神经网络模型图的protobuf格式存储文件。
公告
FPGA可以做什么?信号处理,高速接口,图像处理,深度学习,AI加速......。一起探索新技术新应用,用FPGA做点有趣的事!
联系方式



 绵绵不绝
绵绵不绝  打工人
打工人  2koo
2koo  Fabbi小妃比
Fabbi小妃比  是名一鹿
是名一鹿  Aum★Ken
Aum★Ken  聚乙烯
聚乙烯  so?
so?